République
Française
Votre question porte sur autre chose que cette réutilisation ? Visiter notre forum
1 discussion
Cluster
Bonjour,
C'était pour savoir s'il était possible que vous m'expliquiez comment vous avez réalisé votre clustering.
En effet, je travaille en ce moment sur le clustering dans le cadre d'un projet pour mon année de prépa.
Cordialement
Salut,
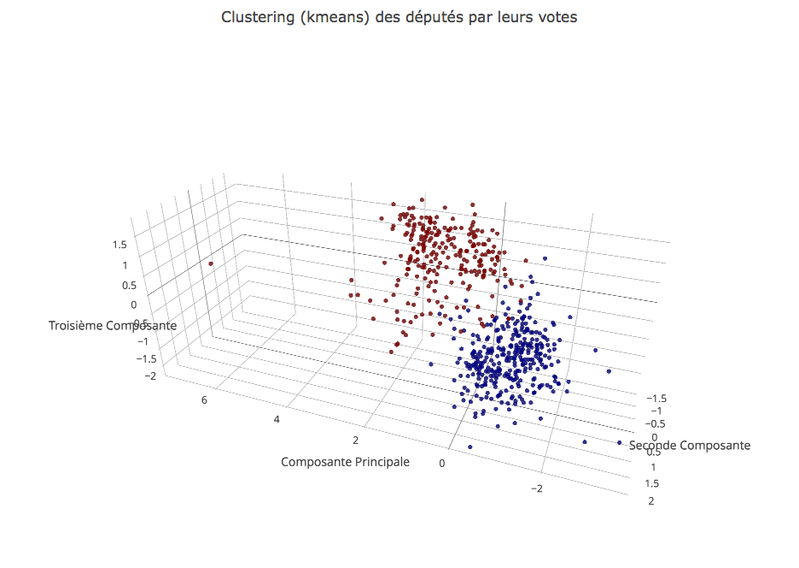
En gros ce clustering il est basé sur les données des votes des parlementaire de la dernière legislature (http://data.assemblee-nationale.fr/travaux-parlementaires/votes) qui bizarrement n'apparaît pas sur ce site. Dans ce fichier les députés sont identifiés par leur N° d'identification et j'utilise ensuite le le fichier ici (marqué comme réutilisation) pour leur donner leur vrai nom. En gros je classe les députés selon comment ils ont voté sur les différentes lois. A partir de la façon dont ils ont voté je crée un vecteur (en gros 0 -> contre la loi, 1 -> pour la loi, 2 -> abstention, etc...) et j'utilise ça pour les classer.
Pour ce qui est du clustering, j'utilise l'algorithme k-means qui est l'un des plus simple :
Initialisation :
Déjà tu choisis le nombre de cluster que veux (ici j'ai du choisir deux parce que je voulais voire les députés gauche droite, mais ca marche avec plus, si tu veux voire des centristes (etc...).
Pour chaque cluster que tu veux tu l'initialise avec un vecteur (au hasard).
Iteration:
Ensuite tu classe tous les vecteur selon leur proximité avec les cluster (tu calcule la distance (selon la norme de ton choix) entre les vecteur et la position des cluster et tu rattache chaque vecteur au cluster plus proche.
Ensuite tu vas calculer une nouvelle position pour chaque cluster qui va être le barycentre (la moyenne) de tous les vecteurs appartenant a ce cluster.
Terminaison :
Tu itère jusqu'à que les cluster ne changent plus d'une iteration à l'autre.
Voila pour l'algorithme k-means, mais il y'en a pas mal d'autres (j'ai plus trop les noms en tête mais google doit pouvoir t'aider).
Pour ce qui est de la representation graphique, c'est de l'ACP (analyse en composante principale) qui permet de te donner les vecteurs (ou directions) selon lesquels projeter les points pour maximiser les écarts. La non plus j'ai plus trop en tête l'algorithme exacte (c'est des histoires de matrices de covariance me semble-t-il).
Voila, j'espère avoir répondu au moins en partie a tes questions et je te souhaite bon courage pour ce que j'imagine être un TIPE :)
Cordialement
Merci beaucoup pour vos précieuses informations.