
Données ouvertes du Grand Débat National
Par Service d'Information du Gouvernement
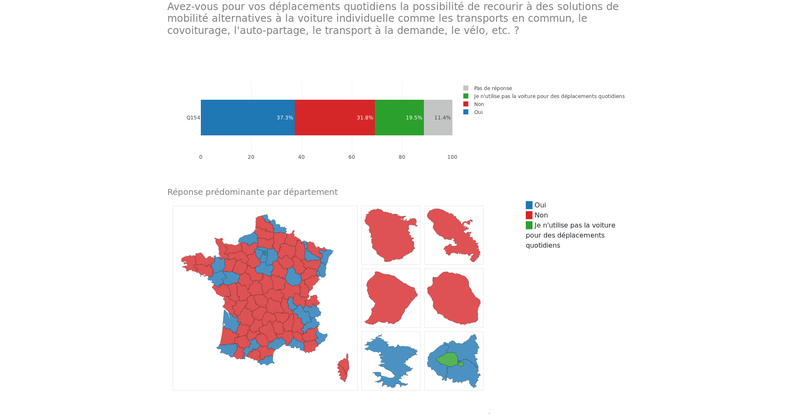
Le Gouvernement est attaché à la transparence du Grand Débat et cette exigence de transparence est également portée par le collège des garants. Ainsi, l’ensemble des contributions au débat, qu'elles aient été envoyées par voie postale, par courriel ou via les formulaires en ligne, seront à terme…
Qualité des métadonnées :
Description des données renseignée
Fichiers documentés
Licence renseignée
Fréquence de mise à jour respectée
Formats de fichiers standards
Couverture temporelle renseignée
Couverture spatiale renseignée
Tous les fichiers sont disponibles
Mis à jour il y a 1 jour