Visualisation des données issues de l'annotation
Visualización
Published on 9 de julio de 2021 by Datactivist
This is a degraded experience of data.gouv.fr. Please enable JavaScript and use an up to date browser.
Mandaté par Datactivist, la Licence Professionnelle Médiations de l’Information Numérique et des Données 2020/2021, accompagnée par Samuel Goëta, a conduit un projet tuteuré ayant pour objectif d’annoter les commentaires publiés sur data.gouv.fr pour permettre leur analyse et, par la suite, la résolution des problèmes et l’amélioration de plateforme.
Ce jeu de données est le fruit de ce travail réalisé par les étudiants de la Licence Professionnelle Médiations de l’Information Numérique et des Données (LP MIND) de l’Université Bordeaux Montaigne, promotion 2020/2021, dans le cadre d’un projet tuteuré encadré par Olivier LE DEUFF, maître de conférences à l'université Bordeaux-Montaigne et à l'IUT Bordeaux Montaigne, et réalisé par Florian BUCHER, Aurélien CHAIX-RENOU, Zoé DORIZY, Mathilde FERNANDEZ, Emma HERMET, Sophie METSEMAKERS, Aurore QUAGGIOTTO, Blandine SERRE, Naxan SEWDUTH.
Dans le but de s'inscrire dans des bonnes pratiques, la documentation de ce jeu de données suit le modèle Datasheet for Datasets pour faciliter sa réutilisation par le plus grand nombre.
Le site data.gouv.fr est visité par des utilisateurs de milieux différents, autant par des professionnels que par des amateurs, familiarisés à l’utilisation de bases de données ou complètement novices. Par ailleurs, les producteurs de données ne sont pas toujours formés aux bonnes pratiques de production des données ouvertes. Cette double réalité se reflète dans les commentaires, demandes d’aide, questionnements laissés par les utilisateurs sur le site data.gouv.fr.
L'annotation des commentaires postés sur data.gouv.fr vise à :
Ce travail s'inscrit également dans le cadre des réflexions engagés par Datactivist pour Etalab sur la nouvelle feuille de route open data de data.gouv.fr.
Le jeu de données annote l'intégralité les commentaires provenant du fichier discussions, disponible dans le catalogue de données de data.gouv.fr. Les discussions ont été téléchargées en janvier 2021 et traitées en février 2021.
Le jeu de données est disponible au format CSV encodé en UTF-8, séparateurs virgule.
La base de données est composée de ces différents champs :
Les données ont été collectées via le fichier discussion fourni par le site data.gouv.fr (https://www.data.gouv.fr/fr/datasets/catalogue-des-donnees-de-data-gouv-fr/). Le fichier .csv contient un total de 7961 lignes.
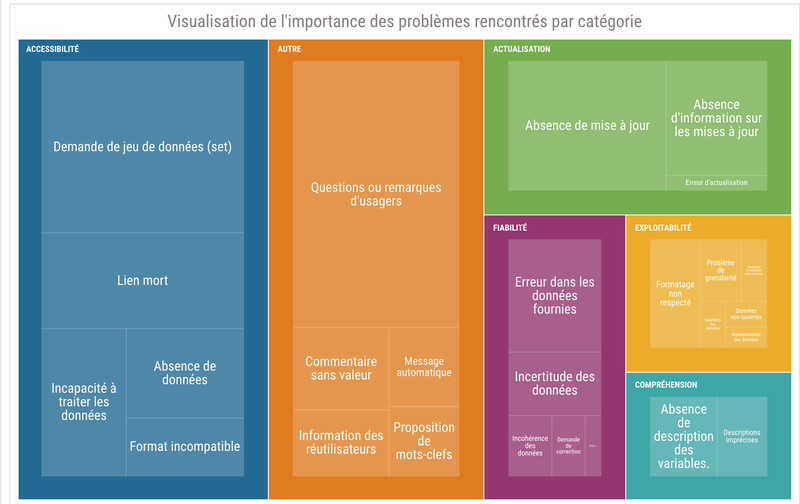
Afin de permettre une évaluation et un cadrage efficace des nombreux commentaires de la base de données, nous avons établi une typologie des problèmes rencontrés afin de toujours pouvoir précisément indiquer l’obstacle rencontré par l’utilisateur. Cette typologie s'appuie en partie sur des travaux d’un groupe de Toronto ayant fait des recherches pour produire des indicateurs de qualité des données. De ce fait, notre typologie reprend certains de ses principes, dont des noms de catégories et certaines définitions.
(https://teamopendata.org/t/toronto-outil-de-notation-de-la-qualite-des-donnees-ouvertes/1579).La typologie est séparée en différentes catégories (Accessibilité, Exploitabilité, Actualisation, Fiabilité, Compréhension, Autre), et chaque catégorie contient plusieurs types de problèmes rencontrés par l’utilisateur.
La typologie figure dans les ressources associées au jeu de données.
Une fois les données récupérées, l’enjeu était de pouvoir analyser et annoter dans Airtable chaque fil de discussion pour pouvoir lui attribuer un type de problème selon la typologie sélectionnée. Cette dernière a été éprouvée sur un échantillon d’une centaine de commentaires, dont le traitement a été séparé en 9, selon le nombre de participants à l’annotation. Si des problèmes étaient rencontrés lors de l’annotation, le groupe se concertait et corrigeait la typologie (ajout d’un type de problème, rectification d’une définition de problème…)
Lors de l’annotation, les consignes suivantes sont appliquées :
Après cette phase d’essai, l'entièreté de la base de données à été séparée en 9 parties, selon le nombre de participants à l’annotation. Deux groupes de correction ont été créés pour permettre une reprise plus rapide des annotations de chacun. Une décision collégiale est prise pour les cas les plus compliqués, qui étaient souvent des commentaires présentant plusieurs types de problèmes et dont nous devions hiérarchiser le problème pour n'ajouter qu’un type de problème unique.
Il n’y a eu aucun travail de pré-traitement pour ce jeu de données. Le fichier a été récupéré en l’état, et les données brutes sont donc disponibles sur le site data.gouv.fr, en pied de page, sous le lien “catalogue des données”.
Le jeu de données est diffusé sur le portail data.gouv.fr avec le compte Datactivist sous Licence ouverte comme la licence initiale du catalogue de data.gouv.fr.
Pour citer ce jeu de données, indiquer : source LP MIND 2020/2021 du 25/02/21
Ce jeu de données est l'œuvre d’une opération ponctuelle dans le cadre d’un projet tuteuré.
En raison de son caractère exceptionnel, aucune mise à jour n’est prévue.
En cas de question ou de problème, il sera possible de contacter samuel/at/datactivist.coop ou de poster un commentaire ci-dessous.
Le jeu de données d’origine a été publié par data.gouv.fr sous licence ouverte, les informations qu’il contient peuvent donc être utilisées par toute personne, physique ou morale, qui le souhaite.
La plateforme data.gouv.fr a prévu que tout utilisateur publiant un message, cède ses droits de propriété intellectuelle sur ces commentaires à l'administration : “les contributeurs publiant un commentaire dans une discussion cèdent leurs droits de propriété intellectuelle sur ceux-ci de façon non exclusive, à titre gracieux, pour le monde entier, pour toute la durée de ces droits.” (https://www.data.gouv.fr/fr/terms/)
Le jeu de données contient le prénom et nom de l’usager et, dans certains cas, d’autres données à caractère personnelle dans le contenu du message comme des adresses électroniques.
Pour des raisons de sécurité et parce que les données personnelles présentes au sein du jeu de données ne sont pas indispensables à son utilisation et à sa pertinence, nous avons retiré les noms des usagers et les adresses électroniques. Toutefois, en raison de la quantité de commentaires présents au sein du jeu de données (un peu moins de 8000), nous ne pouvons pas affirmer avec certitude qu’aucun ne portera atteinte à la vie privée, ne permettra une appréciation ou un jugement de valeur sur un utilisateur ou ne fera apparaître le comportement d’une personne pouvant lui porter préjudice mais cette responsabilité incombe en premier ressort au producteur.
9 de julio de 2021
Licence Ouverte / Open Licence version 2.0
Data description filled
Files documented
License filled
Update frequency followed
File formats are open
Temporal coverage filled
Spatial coverage not set
All files are available
Spatial coverage not set
Visualización
Published on 9 de julio de 2021 by Datactivist
There are no discussions for this dataset yet.
There are no community resources for this dataset yet.
60e8509fc2e87ea1bcfc7b68
9 de julio de 2021
Irregular
2014/01/01 to 2021/02/01
9 de julio de 2021
1,3k
39
1
5