République
Française
Introducing udata 4
Introducing udata 4, codename: cockroach — you'll see why in a bit!
This a follow up on the latest major release (udata 3) roadmap post.
Our goal here is to highlight the major coming with udata 4 and what we think can be built with it.
It's intended for anyone looking at udata for their needs or already using it. Please be aware, it can get quite technical.
We'll also talk about the community around udata and how we hope to share and communicate in the future.
Architectural changes
Since the release of udata 3, aka snowpiercer, we mainly focused on the development of our new frontend, which was necessary for the graphical overhaul of data.gouv.fr.
We believe this new system is now stable and brought us closer to our ultimate goal, as previously stated: udata should be focused on bringing an API and business logic around an open data catalog. By removing (almost) anything frontend-related to udata-front, we made a big step toward this. As planned, we iterated a lot around this graphical redesign and we did so in a swift manner.
Now that the frontend architecture is out of the way, we can focus on new components, following the same approach: services around udata rather than a fat monolith. Thoses services are (so far):
- the search engine — done! :white_check_mark:
- resources analysis — doing 👷♀️
- and some perspectives!
If you're a udata user, you should know that, moving forward, you'll either:
- need to keep up with the new services we're adding to be feature-par with data.gouv.fr,
- live without those features,
- or plug in your own services.
Search engine
Our search engine has long been a frustrating part for the users of data.gouv.fr. Searching through 40k+ datasets with often poor metadata can be a daunting experience and is a true technical challenge.
That's why we decided to rebuild our search engine from the ground up. We relied on an old version of ElasticSearch, tightly coupled to a lot of udata code. Our goals were to:
- regain control of the search engine by whacking through technical debt
- improve our search results relevance
- uncouple the search service from
udata
In order to do that, we built udata-search-service. It's responsible for managing the search index: (de)indexing search metadata for every object and sending back search results given a query.
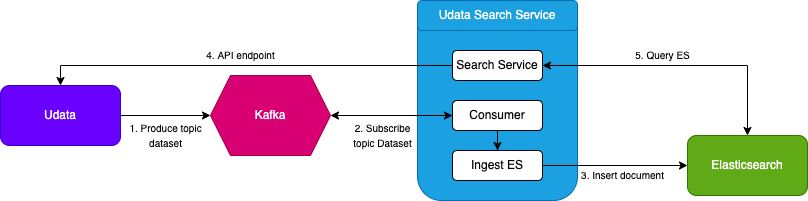
You'll notice Apache Kafka has been introduced in this architecture. It acts as a broker between udata and udata-search-service for indexation purposes.
While the usage Apache Kafka is largely overkill for this scenario, we believe that moving towards an event based model, through Kafka, will allow us to build powerful services around udata. You should also know why this release has been dubbed cockroach now :-)
API changes
We made a difference between list endpoints and smart full-text search endpoints. Existing list endpoints in API v1 (/api/1/datasets) still exists but is based on Mongo lists. It is the case for organizations, datasets, reuses and users. Some parameters have been dropped, but a q parameter is still supported.
The smart full-text search is now optional and is enabled by setting the SEARCH_SERVICE_API_URL setting. It is now defined in API v2 with the following url pattern: /{object}/search (ex: /datasets/search). This endpoint makes an HTTP request to a remote server with the query and parameters. You can easily plug your own full text search engine API here or use our own udata-search-service!
Finally, the suggest endpoints now use mongo contains instead of a smart full-text search. The user suggest endpoint has been dropped.
Resources analysis
One possibility we're very excited about with this new architecture is being able to analyze what's going on in the data we host or link to. Up until now, we almost exclusively focused on metadata and we believed it's time to dig deeper!
We're still brainstorming and experimenting around this, but the architecture could look something like below. As you can see, Kafka becomes a primary citizen and distributes events to and from multiples services:
- udata itself, obviously — udata shall remain the core of the catalog and the primary source of truth on everyting it is responsible for ;
- a datalake that will store all or part of the data we link to — useful for analysis, caching, history... ;
- analyzer tool(s) — we currently focus on csv-detective for guessing the types of columns in a CSV ;
- a remote metadata crawler for detecting changes and errors in remote links — we're currently experimenting with decapode.
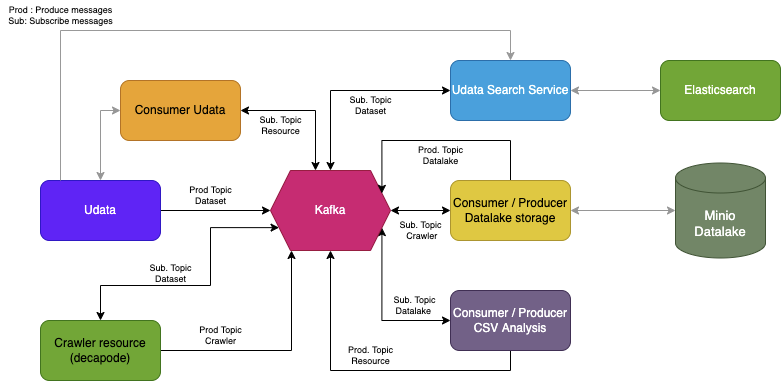
All those services shall communicate through Kafka and enrich whichever service is interested. We're also thinking about communicating with external systems (i.e. services outside our architecture) through a REST gateway.
And more to come!
As stated, we think of the new event-driven architecture as an enabler for future services and features. Thinking long term, it might even be a way to integrate external systems more seamlessly with udata or data.gouv.fr.
The community
The last time we wrote on udata, regarding the v3 release, we highlighted the fact that Etalab was pretty much alone in maintaining udata.
An overwhelming majority of commits on udata have been made by members of Etalab, the French government agency responsible for data.gouv.fr.
The technical team dedicated at Etalab responsible not only for development but also for operating the platform and handling user support has always been relatively small: between one and three people.
We also had lost touch with the main platforms reusing udata for their needs, leading us to focus on our needs first and not so much on the community's.
Since then, we are happy to have had renewed contacts with some udata users, mainly the governments of Serbia and Luxembourg. We felt an increasing need for help and documentation, mainly for dealing with a migration to the latest version of udata.
We heard this and we will try to produce more documentation and give more visibility on our technical choices, hence this post. We also revamped our main documentation quite a bit. A much needed focus on the new metrics (Matomo) collection system has been written too.
If you're interested in udata 4, you can join the community to discuss architectural changes or get started with udata 4 at https://github.com/opendatateam/udata/discussions/2724.
We believe we need a vibrant and responsive community in order for those efforts to be successful. It can be pretty frustrating producing those efforts in the dark.
That's why we need your help! Our first step is opening Github discussions on the udata project. If you're using or are interested in udata, please come and comment on this discussion. Tell us how you're using it, what you're expecting from the community and are willing to give back... Also feel free to open a new discussion if you want to reach out for something broader than a specific udata technical issue (plugins, governance, migration, installation...).
udata releases history
- udata 1 aka uData, our original version
- udata 2 aka lazysnake, which mainly introduced a switch to Python 3
- udata 3 aka snowpiercer, which introduced
udata-frontand a cleaner separation of concern between front and back - udata 4 aka cockroach, which brings a service orientend architecture a step further